blog post: Managing ArXiv RSS Feeds in Emacs
Background
It’s very important for any researcher to keep up with the papers that are being published, especially in the fast-moving field of machine learning.
However, there are a lot of papers from the arxiv categories which I follow, sometimes hundreds of papers a day. Some people use twitter, Reddit etc to find interesting papers. This is definitely better than not following the literature at all, but there’s a risk of missing papers that are relevant to your work. There are some tools that try to use filtering methods to restrict suggested papers to read based on keywords or some learned system. Personally, I use the Fraser Lab method of following literature. This requires exhaustively looking at all the articles, but with a varying amount of attention spent on each one.
Most articles need just a few seconds to look at the title and authors to see if I’m interested in it. For those that I am interested in, I read the abstract to decide whether it would be useful to read the full paper. (At this point, even if I don’t read the full paper I hit the zotero importer to automatically pull it into zotero and my bibtex file in case I later realise it’s worth reading further). For the papers I decide to read, I’ll typically skim the main results in a few minutes, and possibly jot things like the setting or referenced papers which seem interesting. For a handful of papers a week, I’ll read them in more detail and make extensive notes.
Reading a title takes a second or two, reading an abstract takes a few tens of seconds, and skimming takes a few minutes. With the volume of papers that I want to get through, it’s really important to have a system that has good keyboard shortcuts and is easy to navigate, with good links to my main system of notes.
I used to use Feedly to look through papers, but recently I have noticed that it seems to be becoming slower. It displays about half the abstract by default, which is awkward to read, and generally doesn’t display anything in the way that’s best for quick scanning.
There are increasingly annoying items in the feed that are actually adverts that feedly has inserted.
Recently I’ve been using emacs for taking notes and programming, so
I thought it would be interesting to see if it’s possible to process
RSS feeds in emacs. There were a few issues. At first I tried using org-feed, the built-in
RSS-reader for emacs’ org-mode. I managed to get a rudimentary system working, but in the end I
developed a much better workflow using elfeed
Elfeed
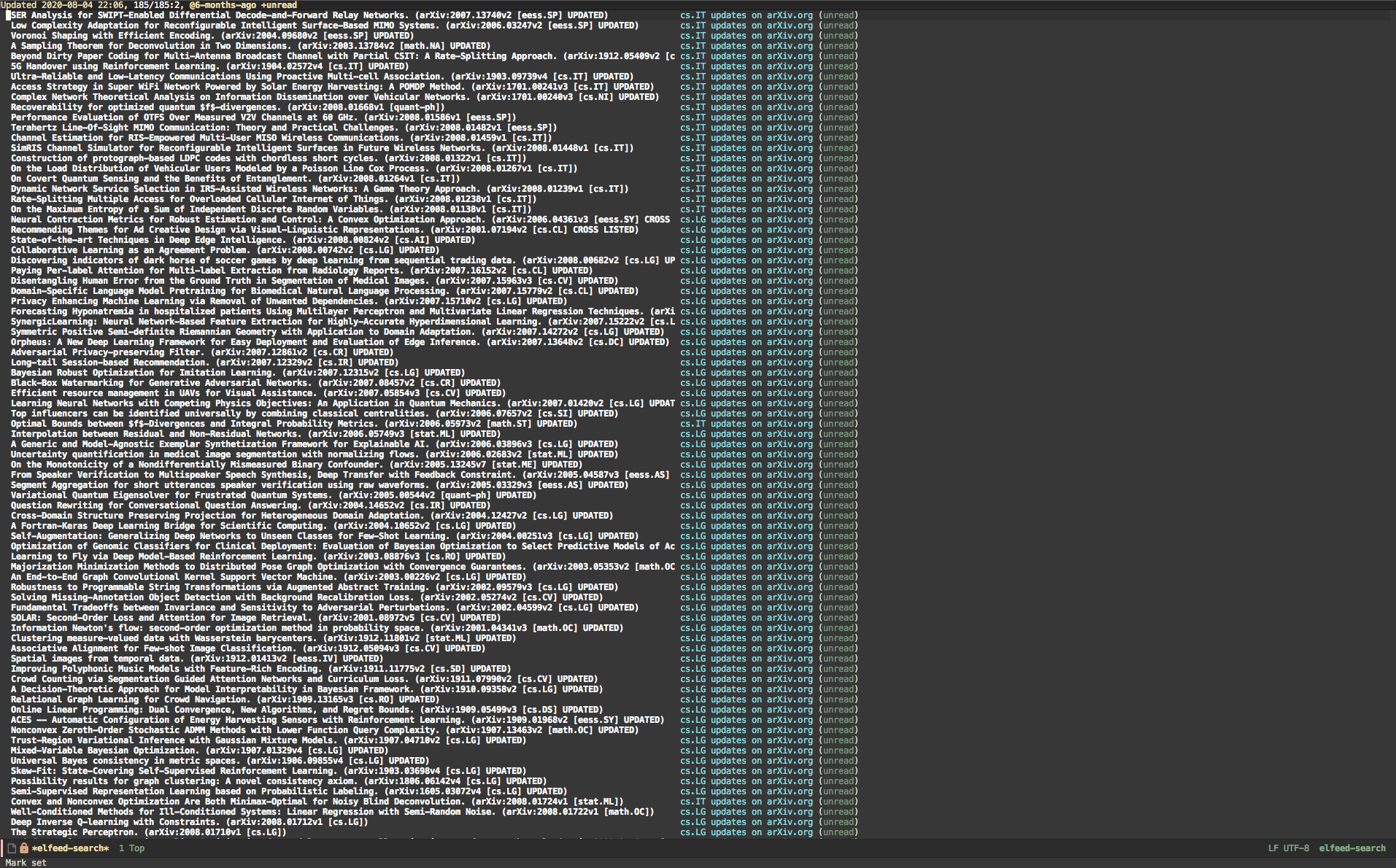
I ended up using elfeed as the main engine to process RSS feeds. The initial user experience really wasn’t optimal, but elfeed is designed really nicely to be very customizable. After (quite a lot of) tweaking, and learning a fair amount of emacs lisp in the process, this is what it looks like now.

Atom Feeds
Although this article is all about keeping up with papers using RSS feeds, the first step was actually
to stop using RSS feeds, and instead use atom feeds. As I discovered while looking into this,
RSS is a bit messy as a standard, while atom is much cleaner. Practically, this means that elfeed
is able to parse atom feeds much more easily than RSS feeds, particularly in parsing the authors of the papers. Therefore, instead of using an RSS feed like
http://export.arxiv.org/rss/cs.LG, I now use an atom feed like http://export.arxiv.org/api/query?search_query=cat:cs.LG&start=0&max_results=300&sortBy=submittedDate&sortOrder=descending.
An extra advantage here is that the RSS feed is updated on a certain schedule and the content is always the most recent batch of additions, while the atom feed can be tuned to have the last \(n\) items. This way it’s not so vital that you always download the RSS feed before it changes again – there’s a bit of a buffer available. I picked 300 as a number that should be comfortably larger than the most papers published in a day in the most active arxiv categories. In retrospect, it may make sense to go for an even larger number, to build up a buffer if you’re not able to check arxiv for an extended amount of time. On the other hand, the larger the number then (presumably) the longer it will take to fetch all of the papers whenever you run elfeed-update. Of course you can always temporarily increase the number if you’re coming back to arxiv after a holiday or something like that.
Elfeed-org
I also use elfeed-org to input my feeds. It seems very difficult to specify a custom name for the feed without using this package.
I active this by putting the following in my .emacs:
(require 'elfeed-org)
(setq rmh-elfeed-org-files (list "~/.emacs.d/elfeed.org"))
(elfeed-org)
My elfeed-org file looks like this:
* Arxiv :elfeed:
** [[http://export.arxiv.org/api/query?search_query=cat:stat.TH&start=0&max_results=300&sortBy=submittedDate&sortOrder=descending][Stat]]
** [[http://export.arxiv.org/api/query?search_query=cat:cs.LG&start=0&max_results=300&sortBy=submittedDate&sortOrder=descending][LG]]
This imports the last 300 items from the statistic theory and machine learning arxiv feeds.
New elfeed-search-print-entry-function
The next thing is to change how the entries are displayed. We would really like a very wide column for paper title, and a wide column for the authors. The specific arxiv feed the paper comes from isn’t that important, and the unread status is not very useful since we’re only typically going to be looking at the unread papers. Maybe there could be some interesting application for tagging certain papers and looking at the tags, but I can’t think of a really compelling use for me.
The main aim we have is to get the authors and display them alongside the paper title. In elfeed, each entry has a property list with various metadata. There is an entry for each author of the entry, which has an entry with the name of the author. So we need a small helper function to concatenate the authors of an entry into a string:
(defun concatenate-authors (authors-list)
"Given AUTHORS-LIST, list of plists; return string of all authors
concatenated."
(mapconcat
(lambda (author) (plist-get author :name))
authors-list ", "))
We’re ready to define the new elfeed-search-print-entry-function. This is the function that handles formatting of the main elfeed buffer, the elfeed-search view.
(defun my-search-print-fn (entry)
"Print ENTRY to the buffer."
(let* ((date (elfeed-search-format-date (elfeed-entry-date entry)))
(title (or (elfeed-meta entry :title)
(elfeed-entry-title entry) ""))
(title-faces (elfeed-search--faces (elfeed-entry-tags entry)))
(feed (elfeed-entry-feed entry))
(feed-title
(when feed
(or (elfeed-meta feed :title) (elfeed-feed-title feed))))
(entry-authors (concatenate-authors
(elfeed-meta entry :authors)))
(tags (mapcar #'symbol-name (elfeed-entry-tags entry)))
(tags-str (mapconcat
(lambda (s) (propertize s 'face
'elfeed-search-tag-face))
tags ","))
(title-width (- (window-width) 10
elfeed-search-trailing-width))
(title-column (elfeed-format-column
title (elfeed-clamp
elfeed-search-title-min-width
title-width
elfeed-search-title-max-width)
:left))
(authors-width 135)
(authors-column (elfeed-format-column
entry-authors (elfeed-clamp
elfeed-search-title-min-width
authors-width
131)
:left)))
(insert (propertize date 'face 'elfeed-search-date-face) " ")
(insert (propertize title-column
'face title-faces 'kbd-help title) " ")
(insert (propertize authors-column
'face 'elfeed-search-date-face
'kbd-help entry-authors) " ")
;; (when feed-title
;; (insert (propertize entry-authors
;; 'face 'elfeed-search-feed-face) " "))
(when entry-authors
(insert (propertize feed-title
'face 'elfeed-search-feed-face) " "))
;; (when tags
;; (insert "(" tags-str ")"))
)
)
(setq elfeed-search-print-entry-function #'my-search-print-fn)
I put the this in my .emacs file. I needed to fiddle with the number at the end of the (authors-column) s-expression in order for the display to fit properly on my screen. I also commented out the tags display since I don’t use tags. This defines a view with a wide paper name column, a wide authors column, and a narrow space to list which feed the paper came from.
The next thing was using the fork of elfeed from
alphapapa to provide excerpts. With this, I can press `e’ while my cursor (in emacs terms, the point)is on an entry and it will pop open the abstract directly in the page, instead of having to go onto the entry itself to read the abstract. This would require pressing enter and then q to go back. It’s not a major feature but it’s nice-to-have. To do this I just swapped in the fork file in my ~/.emacs.d/elpa/elfeed.
Elfeed-score
The final feature I implemented has been really useful in efficiently scanning the latest papers. This is using the elfeed-score package to score each of the papers based on keywords, and then present the papers in a sorted order, with the highest-scoring papers first. I still want to look exhaustively at the titles of nearly all papers, since I don’t want to miss any papers. Nevertheless this ranking gives me a weak indication of which papers will be interesting, since they will appear first in the buffer. Elfeed-score can also mark papers as read (effectively removing them from the presented papers) if the score is sufficiently negative. I set this negative threshold pretty low to avoid false positives, but it does mean I can avoid papers like Optimal Pacing of a Cyclist in a Time Trial Based on Experimentally Calibrated Models of Fatigue and Recovery which I’m not particularly interested in, while still looking at a broad set of arxiv categories for things I am interested in. You can get similar features from websites such as arxiv-sanity, but I personally like having a more interpretable model instead of the black-box tf-idf SVM used by arxiv-sanity–I don’t want an interesting paper hidden from me for some unexplainable reason.
The documentation for elfeed-score is pretty good, so I won’t go into a full explanation of how it works here. I added in a feature to also score entries by author, so that I can push up authors whose work I will nearly always want to read. This is now implemented into the main elfeed-score package after I submitted a pull request and
Michael volunteered his time to merge it into the main branch.
As an idea of what’s possible with this package, a subset of my ~/.emacs.d/elfeed.score is as follows:
((version 4)
("title")
("content")
("title-or-content"
("uncertainty" 50 10 s 1597198724.419375)
(".*[- ]ODE[- s].*" 100 20 R 1596818708.18127)
(".*[- ]random matrix[- s].*" 100 20 r 1596147179.725621)
(".*[- ]dirichlet[- s].*" 100 20 r 1597198721.238662)
(".*[- ]stein[- s].*" 100 20 r 1596147214.049719)
(".*[- ]beamforming[- s].*" -600 -50 r 1597198241.488021)
("disease" -100 -10 s 1597198723.738764))
("tag")
("authors"
("Stefano Ermon" 300 S nil)
("David Silver" 300 S nil)
("Rezende" 300 S nil))
("feed")
(mark -600)
("adjust-tags"))
I mainly use the title-or-content field now, which matches against the title and content. So the field (".*[- ]ODE[- s].*" 100 20 R 1596818708.18127) is a case-sensitive (specified by the R) regexp matching against any of " ODEs”, " ODE “, " ODE-", etc.
If a match occurs in the title it adds 100 to the score of the entry. If a match occurs in the content field (for us, this is the abstract of the paper) it will add 20 to the score of the entry. The scale is arbitrary, but I’m aiming for a score of 0 for papers I may want to read, 100 for papers I will probably want to read, 200 for papers I will very likely want to read, and 300 for papers I will certainly want to read. I generally put the content matches with a lower score since they may occur multiply times and e.g. I don’t want to miss an interesting paper just because one of the applications was an area I’m not interested in.
I have moved towards using regular expressions since simple matches run the risk of matching against unintended targets. For example, giving a slight negative weight to the string “sport” would give a negative weight to “optimal transport”, which I’m actually quite interested in. We can do something like match against " sport " but this will miss if we have the word “sports”, and so on. The current regular expression is an attempt to capture more of these cases. The (mark 600) expression marks an entry as read if it’s at a score less than -600, which is generally only an entry with a large number of matches giving negative scores
To activate elfeed-score, we just put this in the .init file,
(require 'elfeed-score)
(elfeed-score-enable)
(define-key elfeed-search-mode-map "=" elfeed-score-map)
and the elfeed buffer is sorted after running elfeed-update. Hitting =v will also sort the entries, and =g will reveal the score of the entry, which can be used to investigate if an entry seems to have the wrong score.
Automatic elfeed-updates
Finally I set elfeed to run elfeed-update every 8 hours with the following snippet in my .emacs. Of course if emacs is not opened in a long time then this will not run, but since I use emacs every working day this shouldn’t be a problem.
(run-at-time nil (* 8 60 60) #'elfeed-update)
Conclusion
After all that work, I now have a way of reading the latest papers that:
- Automatically fetches the latest papers every day from the arxiv sub-areas I’m interested in
- Displays the paper title in full along with the authors
- Has convenient keyboard shortcuts so that in seconds I can mark papers as read, pop open the abstract to read more or open the full paper
- Scores the papers based on keywords in the title and abstract, as well as by author names so that I can look over the literature faster.
It’s not a perfect system. I’m not sure how the system currently handles papers that are cross-posted on multiple arxiv categories, or how the system deals with updated papers. In practice these don’t happen often enough that it’s a real issue, but it would be nice to sort those out. However, it’s a huge improvement over my previous method of using feedly and having to deal with adverts and a clumsy system.
I hope this write-up can help if anyone’s thinking about keeping up with the literature in emacs!