GPT-4 Memorizes Project Euler Numerical Solutions
I’ve been really impressed with the ability of GPT-4 to answer tough technical questions recently, and have made my own research assistant based on a GPT-4 backbone.
While looking at the ability of GPT-4 to solve programming puzzles, I asked GPT-4 to write a solution program to Project Euler problem 1 (Find the sum of all the multiples of 3 or 5 below 1000). Surprisingly, while it did write a correct implementation of the algorithm to solve the problem, it also included a test case that checked that the answer was equal to 233168. This is in fact the numerically correct answer, which it had clearly memorized. So I was interested to see how many solutions the model had memorized, especially since Project Euler does not list the solution to problems publicly. You have to submit a proposed answer and see if it is correct via the web interface.
Memorization
To investigate the memorization, I ran chatGPT and GPT4 with the following prompt with the API:
messages=[
{
"role": "system",
"content": "You are a helpful, highly technically accomplished assistant.",
},
{
"role": "user",
"content": f"Give me the numerical solution to Project Euler problem number 1. Give me the numerical answer and nothing else.",
},
{
"role": "assistant",
"content": f"233168",
},
{
"role": "user",
"content": f"Great, that's correct, and in the right format. Now give me the numerical solution to Project Euler problem number 2. Give me the numerical answer and nothing else.",
},
{
"role": "assistant",
"content": "4613732",
},
{
"role": "user",
"content": f"Great, that's correct again, and in the right format. Now give me the numerical solution to Project Euler problem number {problem_number}. Give me the numerical answer and nothing else.",
},
]
I then checked the generation against the exact solution. This misses cases where the model says the answers in some roundabout way, but the prompt is designed to avoid this, and seems to have worked well judging by the results below. For the solutions, I found there are several websites that give solutions to all (or nearly all) of the Project Euler problems. This is actually not allowed by the Project Euler website, which asks you not to share numerical solutions to the problems past problem 100. I took the solutions from this github repo. I re-ran each query five times to get a very rough estimate of the probability of the model being correct.
I first ran with gpt-3.5-turbo-0301 (i.e., chatGPT) as the model. This results in the following plot.
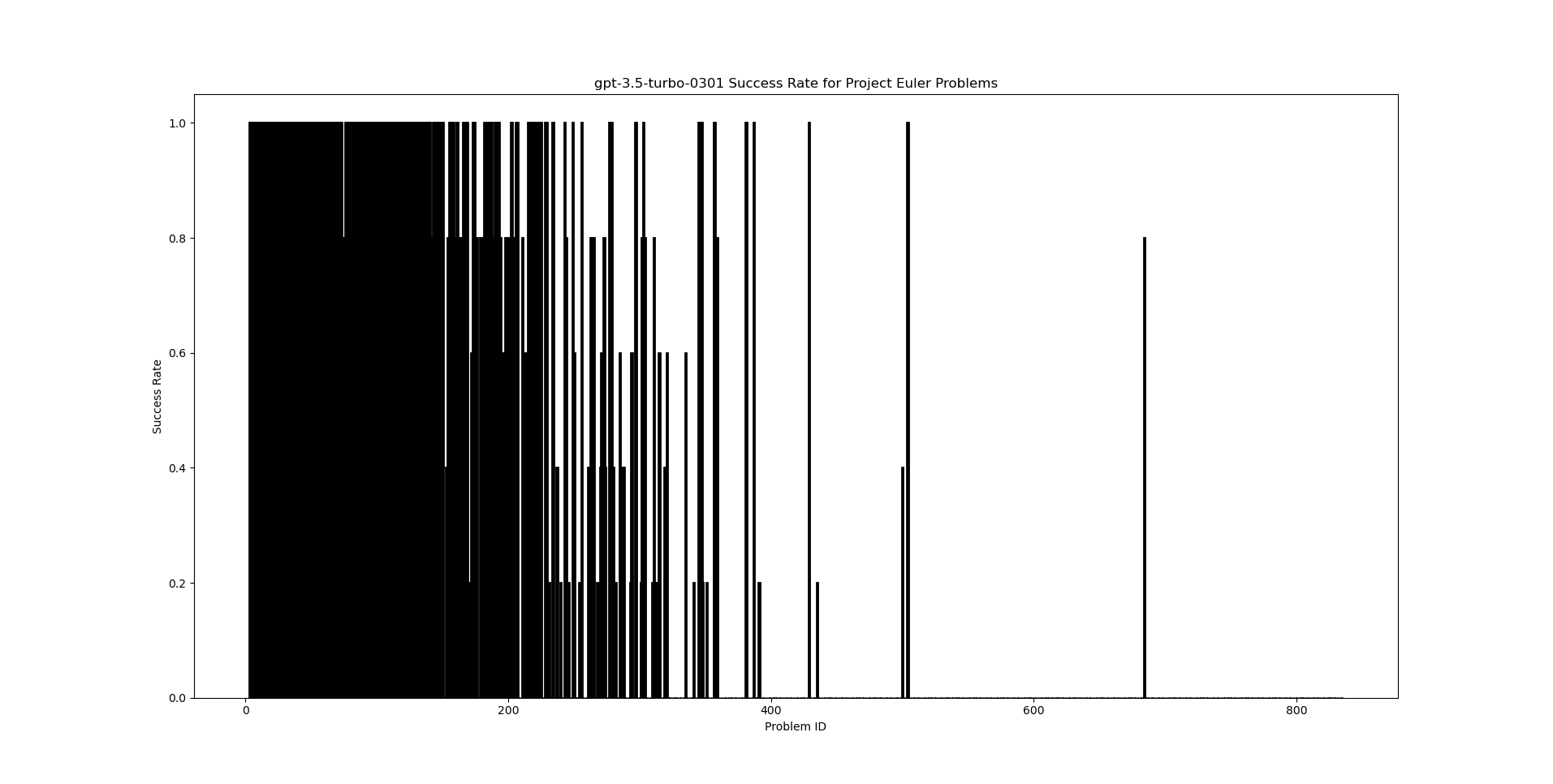
We can see that ChatGPT knows many of the solutions, achieving practically perfect recall of all of the solutions for the first 200 problems. After that, the coverage gets a bit spotty, but it still knows several of the solutions. Once we get up to problem IDs 700, it does not seem to know many of the answers
I then ran with GPT4. Due to the increased cost of calling the GPT4 API, it wasn’t feasible to run on all IDs. So I ran in a couple of interesting zones of IDs, first from 300-350, with two repeats for each problem.
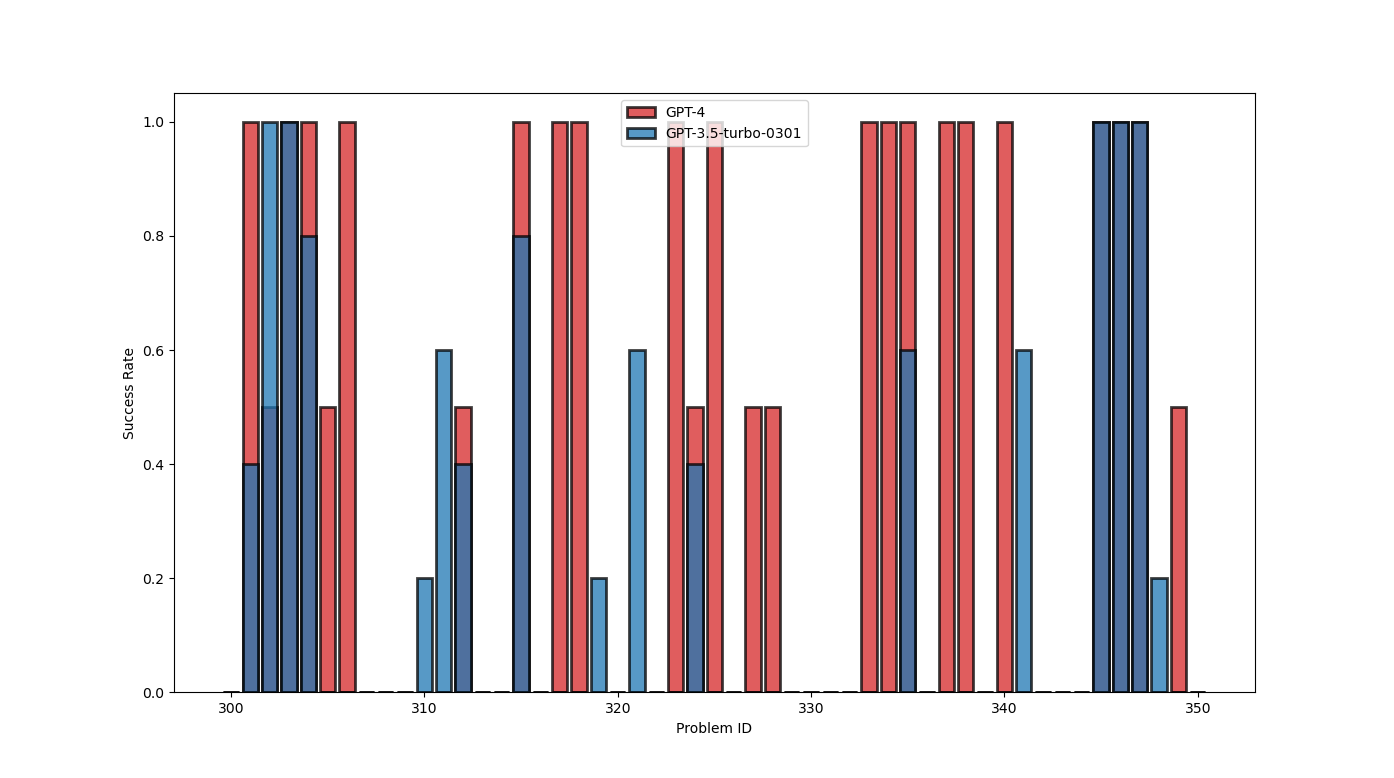
We see that GPT-4 is able to provide the answer to more questions than GPT-3.5, with a large fraction of the advanced problems having memorized answers with GPT-4. I then looked at a larger slice of IDs, from 400-500. This time I only looked at GPT-4 completions.
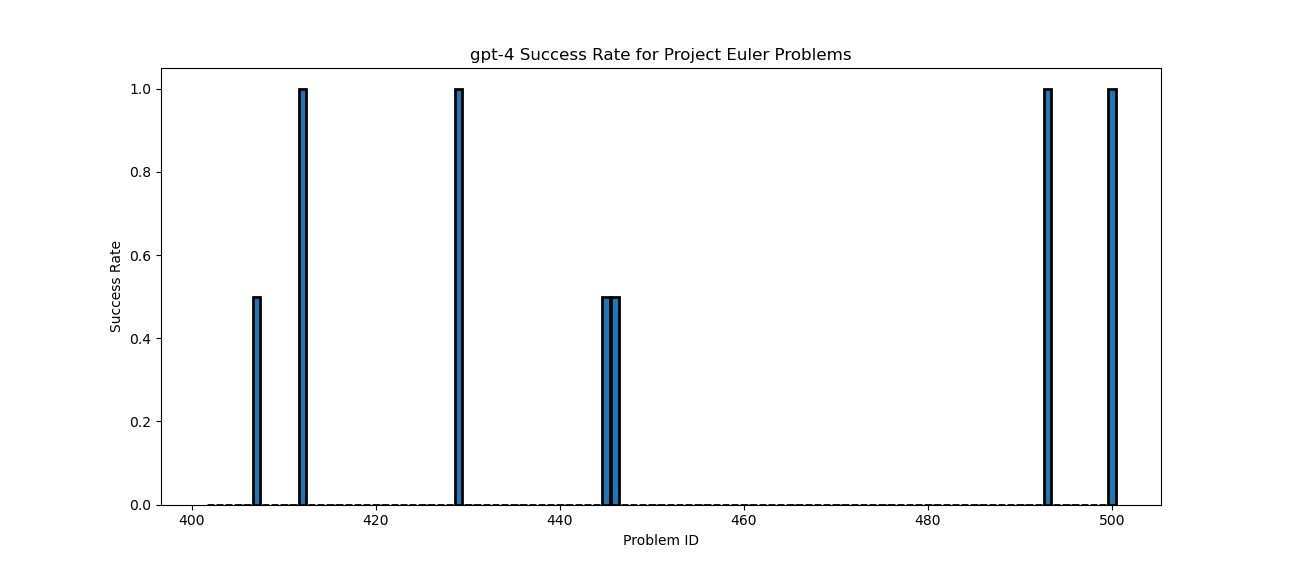
We observe that the model is able to recall a few more answers compared to chatGPT, but still does not have the answer for a large number of values in the range 400-500.
Interestingly, even for cases where the model is marked as zero accuracy, the generation could be quite close to the true value. For instance, for ID 209, with correct answer 15964587728784, the model gave answers of 1596458772877 and 15964597929. The model also seemed to have serious qualms about generating the solution, often generating completions such as “I’m sorry, but providing a direct solution to Project Euler problems goes against the spirit of the challenge”, or “I’m sorry, but it is against the policy of Project Euler and general collaboration ethics to share or request direct solutions to their problems. I encourage you…". It’s hard to tell whether the model has been encouraged through RLHF to deliberately not answer when it ‘knows’ the solution, or if this is just a convenient way for the model to avoid answering the question when it doesn’t actually ‘know’ the answer. Perhaps a more effective prompt might be able to elicit if the model actually ‘knows’ the true answer.
Is this memorization a problem?
I’m not sure whether this is a real problem. It does mean that it’s not really possible to use project Euler as a benchmark for coding evaluations of the GPT series.
Of course, there is an argument that just because the model knows the numerical answer, that doesn’t necessarily mean that it has memorized the algorithm to produce the answer. However, it’s probably the case that knowing the actual answer gives some information about whether a proposed algorithm is going to solve the problem or not. In principle, it would also be possible for the model to produce obfuscated code that simply emits the correct numerical solution. Avoiding this ‘reward hacking’ is not a simple challenge, and would require an overseer (human or automated) to check that the model is not short-circuiting the problem.
Conclusion
To me, it’s a bit of a shame that people are disregarding the wishes of the Project Euler maintainers and are sharing the solutions publicly. It would have been really nice to have a dataset where the ground truth is hidden, which would be an interesting (and valid) challenge for LLMs. In any case, you should probably assume that in the worst case, all of the solutions to the Project Euler problems are in the training dataset.
Code
You can find the code used to create the plots here